Simple Serializable Snapshot Isolation
In A Critique of Snapshot Isolation, published in EuroSys 2012, they present write-snapshot isolation, a simple approach to making snapshot isolation serializable. This work was published a few years after Michael Cahill’s original work on Serializable Snapshot Isolation (TODS 2009), and around a similar time as the work of Dan Ports on implementing serializable snapshot isolation (VLDB 2012), which applied Cahill’s ideas in PostgreSQL.
At the highest level, the idea of this paper is that instead of detecting and aborting “write-write” conflicts, as is done in classic snapshot isolation, it is sufficient to guarantee serializability by instead detecting and preventing “read-write” conflicts. That is, a conflict where one transaction writes to a key that is read by another concurrent transaction. They also show that, at least for some workloads, there is no significant fundamental concurrency/performance impact of this approach vs. snapshot isolation.
Snapshot Isolation
Classic snapshot isolation ensures that each transaction observes a consistent snapshot of the database, and prevents conflicting writes by concurrent transactions. There are standard lock-based and lock-free implementations of SI, which both basically rely on assignment of a “read” and “commit” timestamp to each transaction. That is, a centralized timestamp oracle is used to assign timestamps for ordering transactions. For a transaction \(T_i\) with read timestamp \(T_s(T_i)\), it will read the latest version of data with commit timestamp \(\delta < T_s(T_i)\). Two transactions conflict if they (1) write to the same row \(r\) and (2) they have temporal overlap: \(T_s(T_i) < T_c(T_j)\) and \(T_s(T_j) < T_c(T_i)\) (i.e. their read and commit timestamp spans overlap).

Google’s Percolator system implemented a standard lock-based implementation of SI, which adds lock and write columns, where the write column maintains the commit timestamp. Basically, it runs a 2PC algorithm, and updates the lock column on all modified rows during a first phase of 2PC. If a transaction tries to write into a locked item it may either wait, abort, or force the transaction holding that lock to abort. In second phase of 2PC, the data is then updated with the commit timestamp and the locks removed. Slow or failed transactions that are holding locks, though, may prevent others from making progress.
A basic lock-free implementation of snapshot isolation can be done using a centralized oracle, that is responsible for receiving commit requests from all transactions and checking for conflicts.

This algorithm checks, for each row modified by a transaction, \(R\), whether there is temporal overlap with any other transaction on that row i.e. has any other transaction concurrently written to it. If so, the transaction must be aborted. Otherwise, it is assigned a new commit timestamp and allowed to commit, marking each of its modified rows with the newly chosen commit timestamp.
Serializability
The paper first examines the question of what role write-write conflicts play in snapshot isolation and serializability. The most standard example of non-serializable snapshot isolation histories are those containing write skew anomalies, where transactions don’t write to conflicting keys, but may update keys in a way that violates some global constraint.
They note, though, that aborting transactions on write-write conflicts is also overly restrictive in some ways i.e. transactions will be aborted in some cases even if no serialization anomaly would manifest. They consider a modified variant of the lost update anomaly, like
\[r_1(x) \, \, w_2(x) \, \, w_1(x) \, \, c_1 \, \, c_2\]Standard write-write conflict checks will abort one of these transactions unnecessarily, since a lost update anomaly won’t actually manifest here. As they summarize:
In other words, write-write conflict avoidance of snapshot isolation, besides allowing some histories that are not serializable, unnecessarily lowers the concurrency of transactions by preventing some valid, serializable histories.
Making Snapshot Isolation Serializable
Instead of detecting write-write conflicts of concurrent transactions, as done under classic snapshot isolation, they introduce write-snapshot isolation (WSI), which instead detects and aborts read-write conflicts. They state the conflict conditions more formally as:
- RW-spatial overlap: \(T_j\) writes into row \(r\) and \(T_i\) reads from row \(r\);
- RW-temporal overlap: \(T_s(T_i) < T_c(T_j) < T_c(T_i)\).
Essentially, if a transaction \(T_j\) is concurrent with \(T_i\) and writes a key \(k\) that \(T_i\) reads from, this is manifested as a conflict and \(T_i\) must be prevented from committing. Most importantly, write-snapshot isolation is sufficient to strengthen snapshot isolation to be fully serializable.

They also point out that the simple condition of checking for read-write conflicts is not quite precise enough, and would, by default, lead to unnecessary aborts of read-only transactions. Read-only transactions needn’t abort even if they fall into the conflict detection condition for write-snapshot isolation, since they don’t affect the values read by other transactions, and/or concurrent transactions as well.
They prove that write-snapshot isolation is serializable, by basically showing that you can use commit timestamps of transactions for a serial ordering, and that read-write conflict detection is sufficient to ensure that all transaction reads would be equivalent to those read in a serial history, since they are not allowed to proceed if they conflict with a concurrent write into their read set. And, similarly, the output of writes from each transaction is maintained and respects the commit timestamp ordering.
They present a lock-free implementation of write-snapshot isolation, which augments the classic SI approach by recording both the read sets \(R_w\) and write sets \(R_r\) of each transaction that is used upon transaction commit at an “oracle”.
This is a nice idea since it is mostly the same as write-write conflict detection of SI, just a bit generalized to handle reads as well as writes. Marc Brooker makes some similar observations in a related blog post.
Performance
Their approach raises the question of how different classic SI is from write-snapshot isolation in terms of histories that are allowed or proscribed. Intuitively, it doesn’t seem that there would be something inherently more restrictive about the prevention of read-write conflicts vs. write-write conflicts.
They compare the concurrency level offered by a centralized, lock-free implementation of write-snapshot isolation with that of standard snapshot isolation implementation. They implemented both snapshot isolation and write-snapshot isolation in HBase (an open-source clone of BigTable) to test this. Overall, they test a YCSB workload variant with both normally distributed and zipfian (modeling case where some items are extremely popular) row selection, and find that essentially there is minimal performance difference between the two, at least for these (somewhat artificial) workloads.
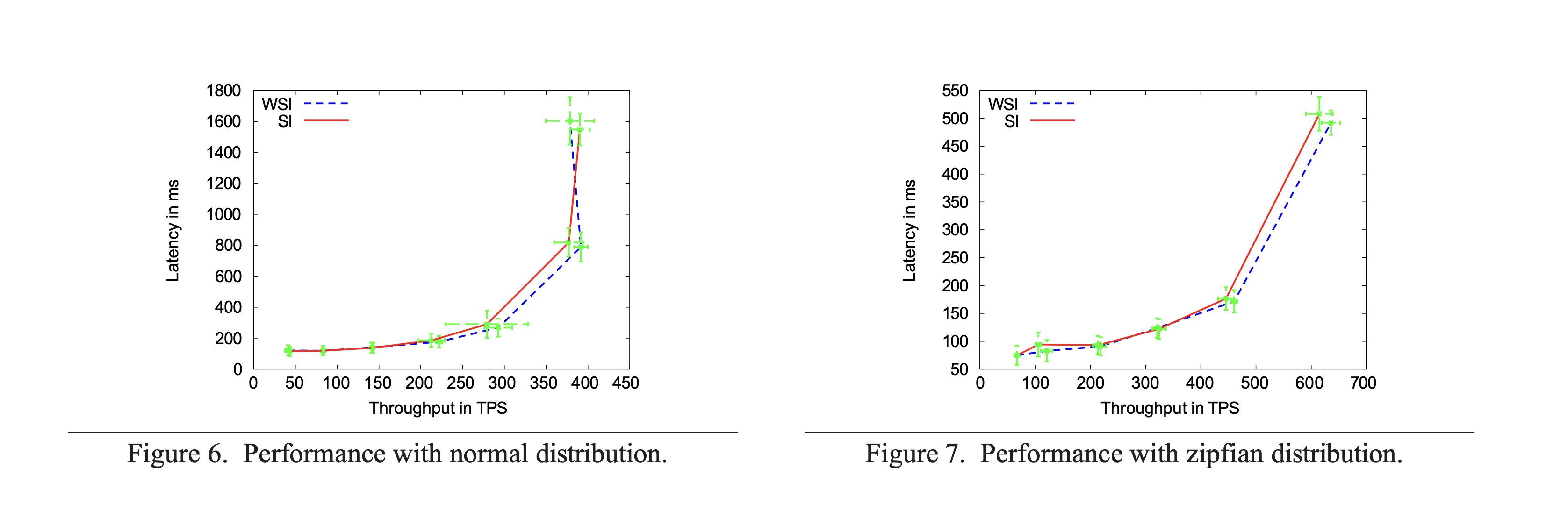
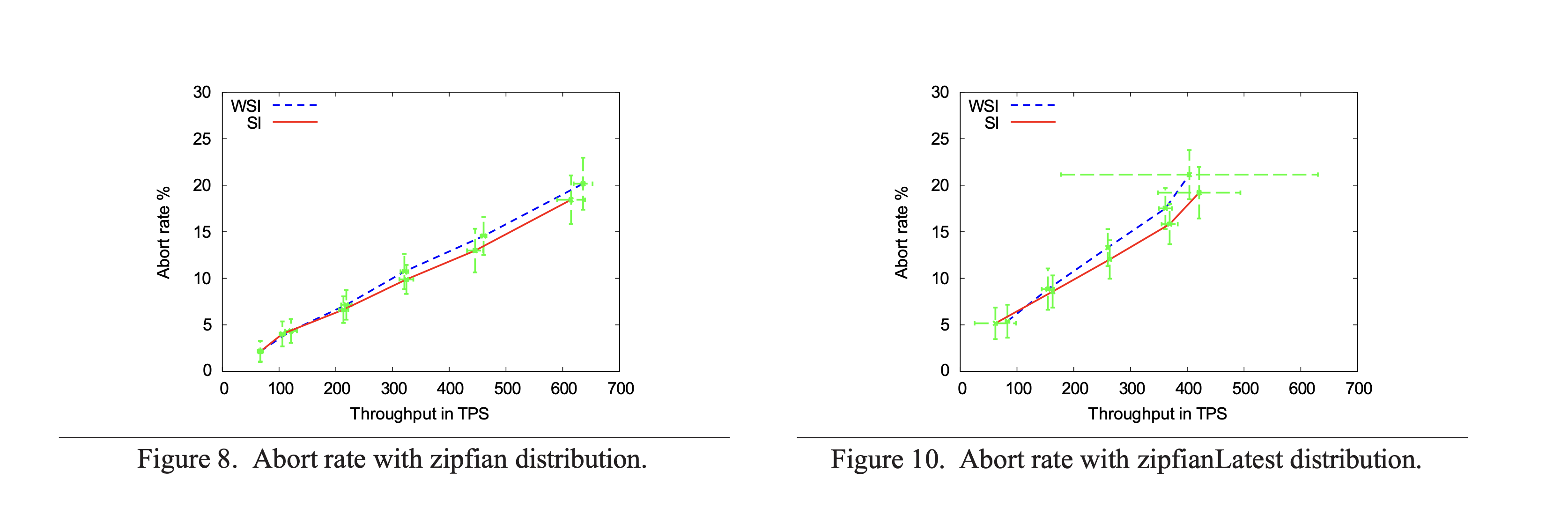
They find similar results for abort rate comparison between SI and WSI, with the latter being slightly higher, but the overall difference is negligible.
Concluding Thoughts
Overall, this paper provides a nice perspective on snapshot isolation in general, and a re-consideration of its underlying assumptions. One takeaway is a reinforcement of the somewhat arbitrary delineations between isolation levels. For example, snapshot isolation is intuitive in some ways i.e. every transaction reads from a consistent snapshot, but the notion of write-write conflicts is somewhat arbitrary. This paper kind of sheds light on that by showing that, in some sense, read-write conflicts are actually the more “natural” type of conflict you would care about, at least in the sense that they give you a more fundamental guarantee i.e. serializability. I’m not sure that the specific anomalies allowed under SI (i.e. write skew) are fundamentally intuitive in any way.
Note that Adya style formalisms and considerations of these type of anomalies center around the concept of anti-dependencies and their appearance in cycles (e.g. the G2 anomaly class). Adya defines an anti-dependency for a transaction that writes a newer version of a value read by another transaction. Cahill’s work on serializable snapshot isolation builds on earlier results from Fekete (TODS 2005), which showed a result that any non-serializable SI history must contain a cycle with 2 consecutive anti-dependency edges, and furthermore, that each of these edges involves two transactions that are active concurrently. For example, in the classic write skew anomaly, such a cycle exists with just two transactions, each with a mutual anti-dependency on the other, satisfying Fekete’s condition. Cahill’s technique basically tracks incoming and outgoing \(rw\) dependencies. This bears similarities to the global approach of checking read set / write set conflicts between transactions, as done in WSI, but using per-transaction metadata.
Some of the ideas from this paper have been more directly implemented in transactional systems like Badger, and are similar to how serializable transactions are implemented in CockroachDB.