Git for Transactions
The idealized model of a transactional data storage system is one of a sequential, serializable system, where clients can submit transactions and the system ensures the outcomes are as if those transactions were executed against a single copy of that data. In practice, performance limitations of this model have historically pushed systems to explore a wide set of alternative, weakly consistent models.
In the weakly consistent world, one approach is to define some reasonable isolation or consistency level that is applicable to a wide enough range of applications, or allow the application to tune the consistency level to their specific needs. Another perspective is to lean even more strongly into the detailed mechanics of the weakly consistent model, abandoning the strictly sequential view of storage, and expose this flexibility to users. This is the type of approach explored in TARDiS (SIGMOD 2016), a concurrency control approach for transactional storage systems that essentially throws out the sequential data store model, and instead adopts weak consistency by making explicit a notion of branch and merge concurrency model.
Essentially, TARDIS adopts a view of transactional isolation and consistency in the style of Git i.e. at the start of a transaction a client forks history onto their own local branch, and are able to perform reads and writes in isolation on this branch. When they have completed their operations, they can go ahead and “merge” back their changes into a main branch of history. TARDiS leaves this merging task to the application, rather than to the underlying storage layer.
Branch and Merge Transactions
The proposed TARDiS system consists of a transactional key-value store that tracks conflicting execution branches with 3 mechanisms:
- branch on conflict
- inter-branch isolation
- application-specific merge
In a standard transactional data store, we can imagine that the entire system consists of a single, linear history of states. As transactions commit, the effects of their write operations are applied to the latest state in this linear history, and new transactions may read from some state in this history (e.g. from either the latest state or some historical snapshot).
TARDiS breaks from this model and instead includes an explicit notion of branching into their data store abstraction. That is, when clients execute transactions, they may can do so in a single mode, which means they are executing their transactions against a chosen branch, or in a merge mode, which allows them to explicitly decide how to merge together conflicting changes across branches. As in Git, branches are conceptually isolated from concurrent transactions, so can be viewed conceptually as their own linear/sequential thread of history by an application.
Begin and Commit
In this model, there are a few natural modifications to the lifecycle of a transaction. First, when a transaction begins, it is not obvious where the transaction will “start from”, since there is no longer a global, sequential state history. So, a transaction first needs some strategy for selecting a branch to being execution against i.e. which state in the history DAG it will begin from, which is called its read state. Similarly, upon commit, a transaction can choose a commit state, which is the state where it will append its new changes to in the history DAG.
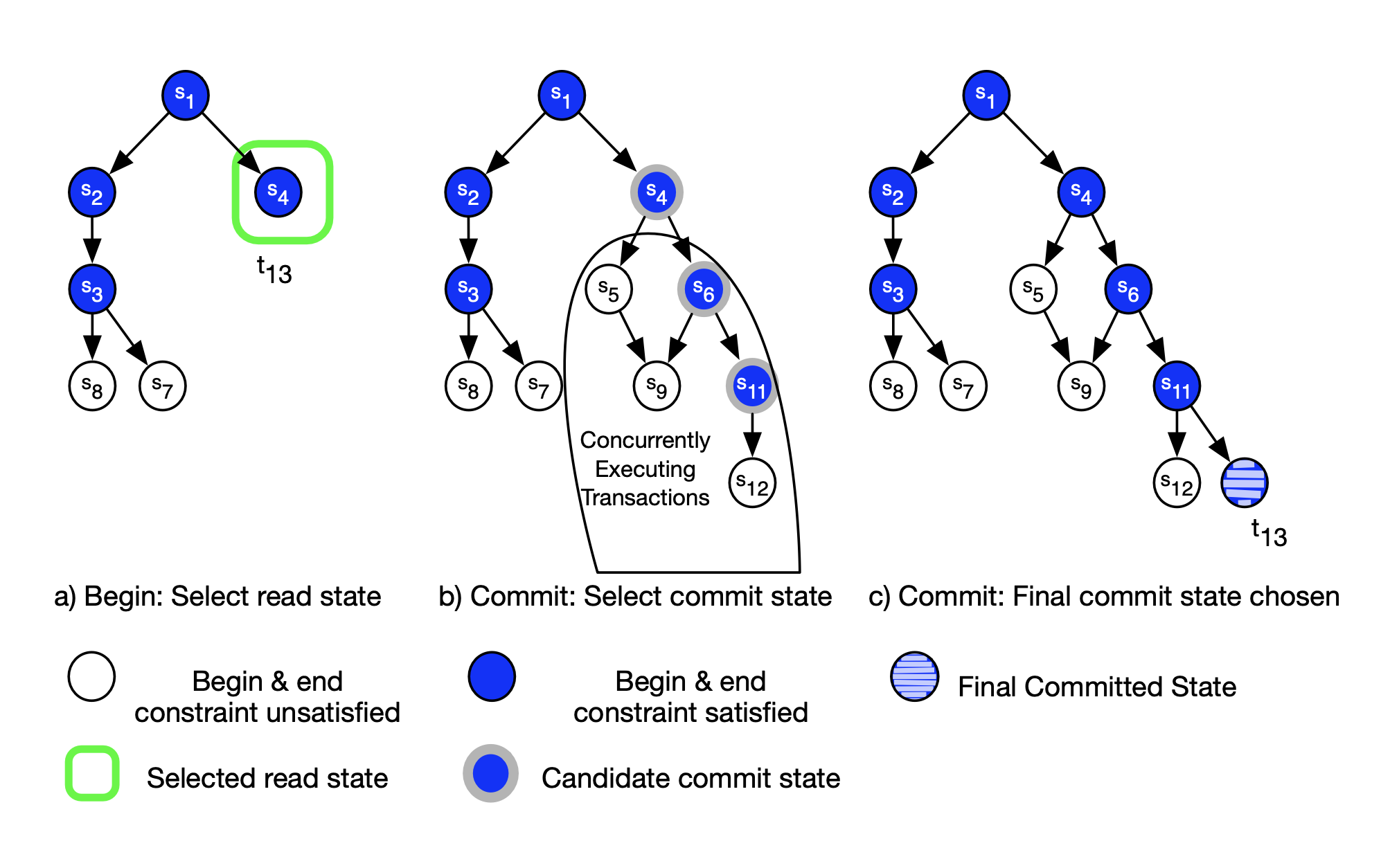
There is also a notion of begin and end constraints, which are additional conditions on start and commit that place extra validity conditions on a transaction, allowing a user more control over the degree of local branching. Essentially, begin constraints place conditions on what read states are valid for a transaction to choose from, and and end constraints place conditions on whether a transaction is valid to successfully commit.
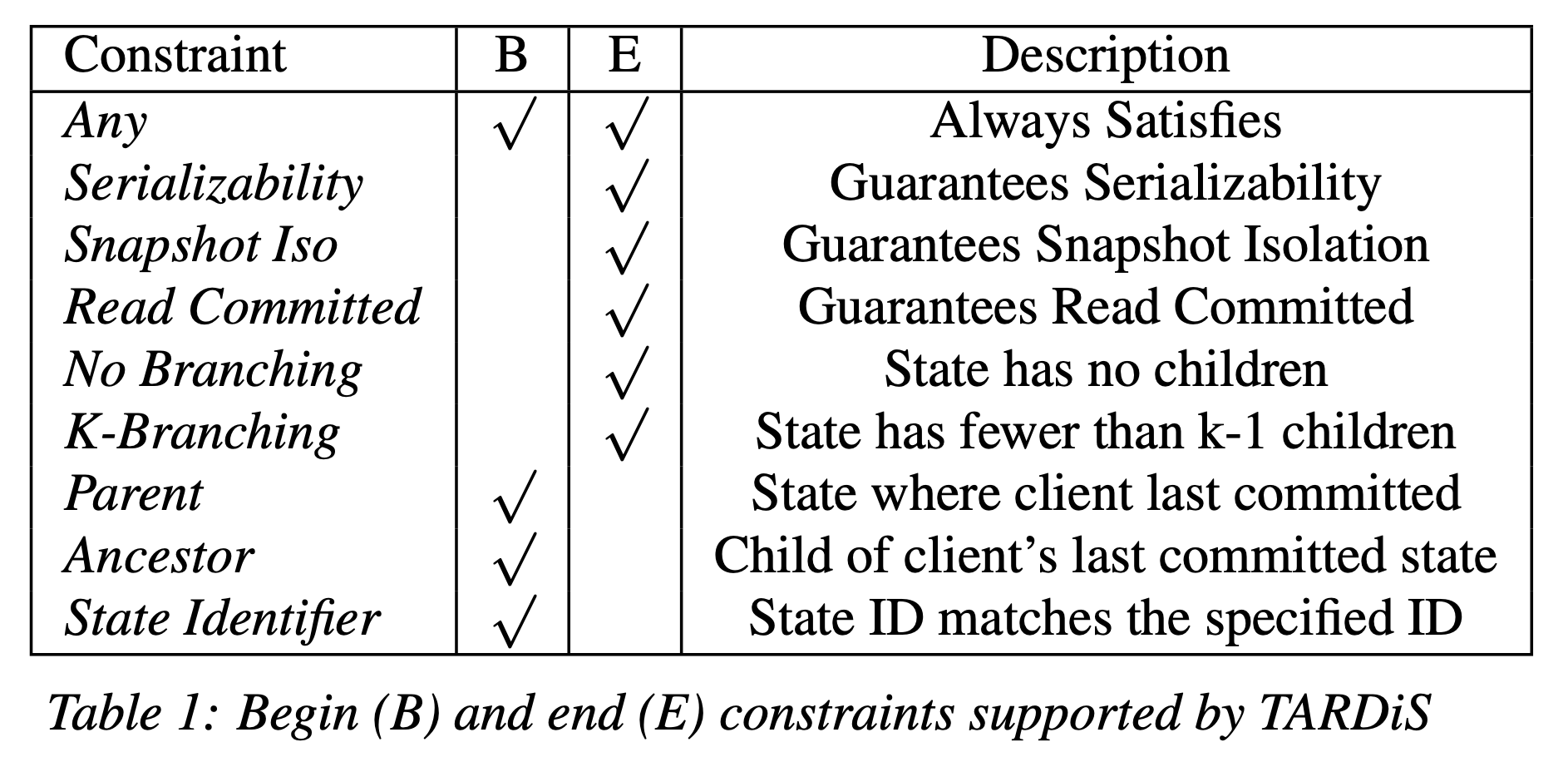
These constraints can be used and composed to guarantee the properties of various standard database isolation levels e.g. snapshot isolation or serializability.
For example, to achieve serializability, one can combine the constraints of
- Begin Constraint: Ancestor
- End Constraint: Serializability, No Branching
These constraints require that a transaction starts from a read state that is the child of its latest committed transaction, and enforces that upon commit, the state does not fork the history. It also will implicitly require tracking of read and write sets of transactions on a branch, since for serializability, we may need to validate that no concurrent transactions intersected with our write/read sets.
There are also constraints for ensuring snapshot isolation e.g. if you do something similar to the serializability constraints but validate write-write conflicts between transactions. The paper does not go into depth on the formal definitions of these constraints, but my impression is that they are sufficient to provide guarantees analogous to these standard isolation levels.
Merging
To make the concept of branch merging explicit, TARDiS includes a concept of merge transactions. Conceptually, these can be viewed as similar to standard transactions in single mode, except that they may operate on multiple read states (i.e. multiple branches). These merge transactions are also a bit special in that they are given access to additional structure about the global state DAG, most notably
- Fork Points: the fork point in the history between the set of states being merged
- Conflict Writes: the set of conflicting writes that occurred on the set of branches being merged.
Access to this information allows merge transactions to explicitly resolve conflicts between branches in an application-specific manner. For example, they take the example of a simple counter value that has diverged among conflicting branches. Given the values on each branch and the fork point, a merge transaction can compute a new, resolved value by summing the difference between the value on each branch plus the value at the fork point.

Concluding Thoughts
It is interesting to note how the ideas in this paper echo the work that came just a bit later, in Crooks work on state-based isolation formalism, which appeared in PODC 2017. It seems that related ideas were present in this work, and the similar ideas were being developed concurrently. For example, the notions of read states and end constraints appear quite analogous to the “read state” and “commit test” concepts in the client-centric formulation. In general, both papers seem to share a common conceptual core of viewing transactional isolation models as centered around state-centric histories i.e. the database moves through a sequence of states over time, and new transactions may conceptually read from one of these states, and upon commit may create a new state, appending to this history.
TARDiS is an interesting attempt at an alternative to managing weakly consistent data interfaces in a more principled manner. On the flip side, my intuition is that managing and merging these branches in a complex application would become burdensome and unintuitive for most application developers. For software and systems builders, and those familiar with Git, DAGs, etc. this may be more palatable, but even in Git I find that it is rare I have ever dealt with merging of more than a 1-2 branches at a time. Even then, dealing with merge conflicts in general can still be somewhat tedious. Perhaps this type of system, though, would be effective as a slightly more internal layer, that other tools/apps could build on top of, rather than having users directly interface with it themselves. Regardless, I think the ideas in the paper are productive and useful as an alternative model for conceptualizing transactions in general and especially weak consistency or isolation models.
They also note that similar ideas have been explored in past, including Olive and Bayou, and there is sort of a folk understanding of the underlying relationships between multiversion concurrency control, Git, snapshot transactions, etc. This also bear similarities to other earlier work on eventually consistent transactions, and to some more recent practical systems primitives like the Merge operator in RocksDB.