Graph
Traversal
We can think about a general graph search/traversal algorithm as
consisting of an visited set of nodes and a frontier
set of nodes. The goal is to eventually have the visited set equal to
all nodes in the graph. The frontier is a set of nodes that we maintain
along the way. Initially, we set the frontier to the starting node of
the graph. It is unexplored but currently on our list of nodes that need
to be explored i.e. it is on the frontier. We then pick a new node from
the frontier set, mark it as explored, and do any other work we might
need to do, and then take all of its neighbors and add them to the
frontier set. In summary, our model is as follows:
visited: Set of nodes we have seen i.e., marked as
visitied.
frontier: Set of nodes that we know about and know are
reachable, but have not yet visited.
We can view BFS and DFS searches as simply variants of this model in
terms of how they select the next nodes to visit out of the current
frontier set.
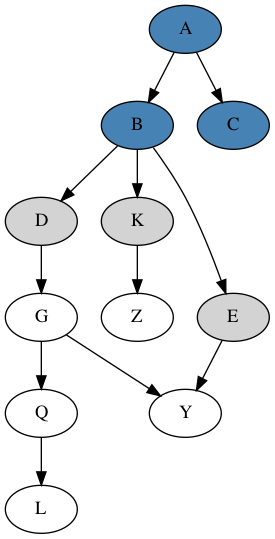
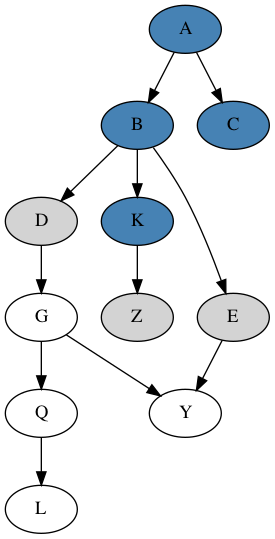
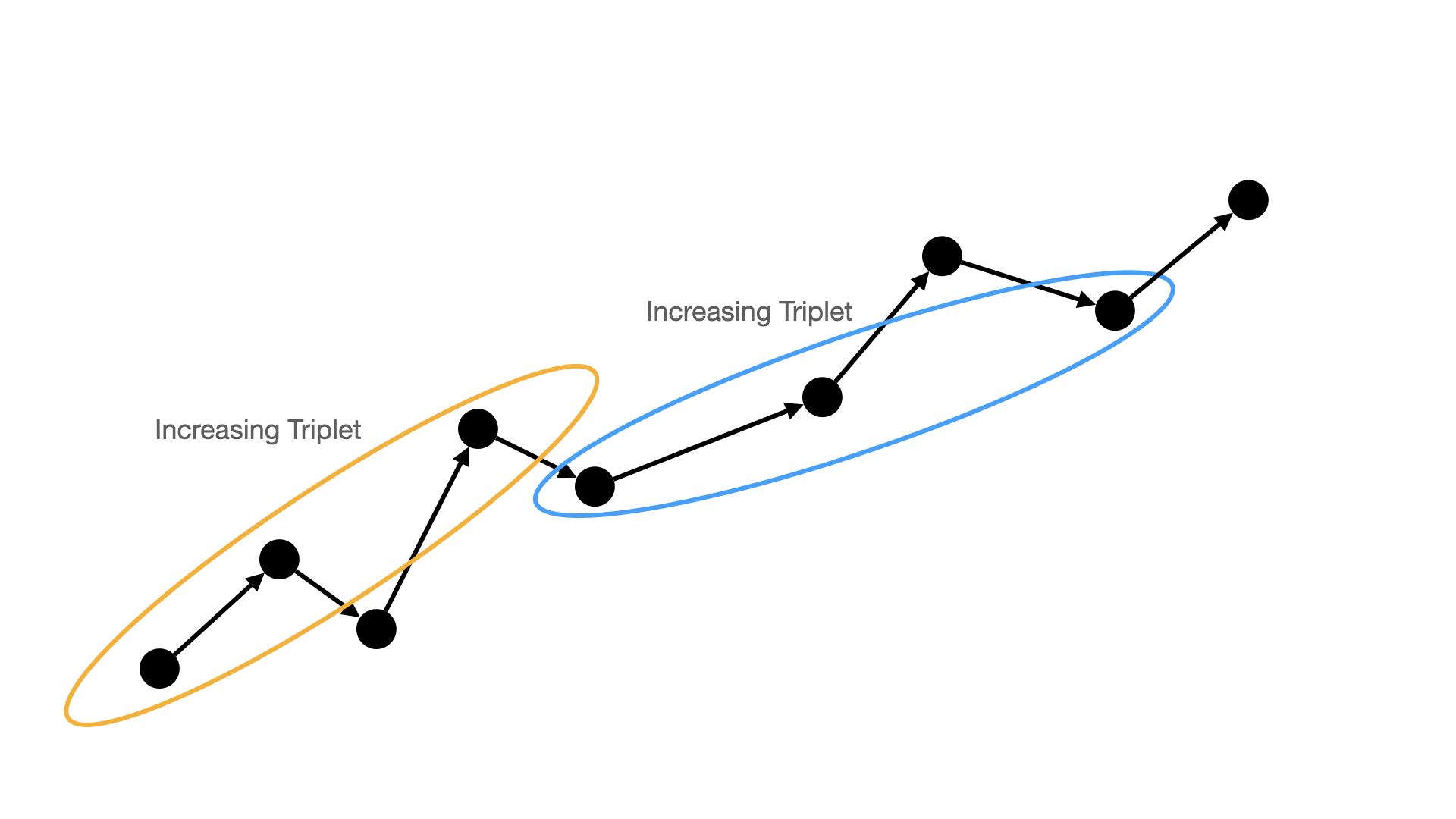
For example, consider two steps of a graph search progression, where
blue nodes as visited and gray nodes as those in the frontier, and node
K is the newly visited node below:
Depth-first search
Depth-first search searches deeper in a graph before searching
broader. Can do a basic recursive or iterative implementation. Iterative
implementation uses a stack to keep track of the frontier nodes, so that
we explore deeper nodes first. We can also implement depth first search
in a way that lets us recover paths to a node, by storing parent
pointers as we go.
Note that if we want to explore a tree, or, more generally,
any acyclic graph, then we can use a depth first search without checking
whether we have already seen a previously visited node. Since,
there are no cycles, the worst that will happen is we may mark a node as
visited multiple times, but we should never get into a nonterminating
loop in the search.
Breadth-first search
Breadth-first search searches all closer nodes before searching
farther nodes i.e. it progresses in “levels" of depth. Not a standard
way to implement it recursively, but can use a queue to keep track of
the frontier nodes.
Dijkstra’s Algorithm
Dijkstra’s algorithm is a way to find the shortest path from a
source node and other nodes in a graph. One way is to view this
kind of shortest path algorithm is as a generalization of other search
algorithms, particularly breadth first search. Essentially, we can
augment the set of visited nodes with some auxiliary information to
track the shortest path to these nodes as we go.
Note first that in the special case of unweighted graph edges,
Dijstra’s algorithm behaves equivalently to breadth first search. That
is, when we add newly discovered nodes to the frontier, we add them all
to the end of a standard queue, since they all have equal distance
(weight 1) from the current node. In weighted graphs, though, this does
not hold, since some nodes may be reachable via lower-weight edges. So,
to generalize this behavior to full Dijkstra, we maintain a priority
queue for the frontier set, which is maintained in order of next
shortest depth from source.
We can also think about each “level" in BFS vs. each “level" in
Dijkstra. In BFS each level has the same depth from source, so can be
interchanged, and will all have depth greater than other nodes in lower
levels in the queue. In Dijkstra, nodes within the same “level" may not
all have the same depth from source, but all nodes within the same level
should have greater depth from source than earlier levels in the
queue.
Also, note that there are a bunch of standard explanations of
Dijkstra’s algorithm where you assume you know all nodes upfront, and
initialize a "visited" distance array for every node. In practice, this
is less realistic since you might not know all nodes of a graph you are
exploring dynamically upfront, and, in general, there is no specific
need for you to have to know all nodes upfront. You can easily just keep
track of nodes distances as you add them into the frontier (priority
queue) set. I find some standard explanations of Dijkstra’s algorithm
more confusing for this reason, since updating nodes as you go helps
make it clearer the basic underlying similarities between this approach
and all other graph traversal algorithms.
Unified Perspective
Overall, we can ultimately see all of DFS, BFS, and algorithms like
Dijkstra’s shortest path as all falling into the same unified graph
traversal framework, except for different conditions on how they choose
to explore nodes in the frontier set. Most generally, we can think about
the frontier set as containing a set of nodes along with their
depth/distance from the starting source node. This depth/distance in
DFS/BFS is used to determine ordering of which nodes are selected next
from the frontier, choosing highest depth first in DFS and lowest depth
first in BFS. Note also that in basic DFS/BFS, these values may
correspond directly to “depth” in the graph from the source, but can be
naturally viewed more generally as “distance", which then allows this
framework to work nicely with weighted graphs.
In Dijkstra’s algorithm, the approach is basically the same as BFS,
except that the “depths” of each node in the frontier set now store
“distance”, which may be computed based on specified edge weights in the
graph. Similarly, for other search algorithm variants like A* search, we
can also choose different selection criterion for how we choose nodes
from the frontier set. Also, we could imagine a basic "random" search
criterion, where we just select nodes from the frontier set arbitrarily.
This would still allow us to adequately explore the graph, but with no
strict properties on how we visit nodes.
In practice, we can use various data structures to store and access
this frontier set more efficiently, but these are all simply
optimizations over the underlying selection conditions. That is, in DFS
we can use a stack, in BFS a queue, and in Dijkstra’s a priority queue,
which is basically behaving the same as a queue in BFS but generalized
to the weighted edge case.
Dynamic
Programming
There are 2 main components of a problem that make it amenable to a
so-called “dynamic programming” (badly named) approach:
Optimal Substructure: A global solution can be
described in terms of solutions to smaller “local” problems. In other
words, it is possible to find a solution to a larger problem by solving
smaller problems and combine them in an efficient way.
Overlapping Subproblems: The global problem can
be broken down into smaller “local" sub-problems, and there is some
overlap/redundancy between these subproblems, which is where you ideally
get the efficiency speedup from.
Note that either (1) and (2), in isolation, don’t necessarily permit
an efficient, dynamic programming based approach to a problem. For
example, we can consider divide and conquer type approaches as
satisfying the optimal substructure property, but don’t
necessarily satisfy the overlapping subproblems property. For
example, merge sort solves smaller subproblems (subsequences of an
original list) and then merges them into a larger solution. But, in
general, these smaller sorting problems cannot be expected to actually
overlap at all.
Examples of problems with efficient DP approaches:
Fibonacci: Compute the \(n\)-th Fibonacci number.
Subset Sum: Given a set (multi-set) \(S\) of integers and a target sum \(k\), determine if there is a subset of
\(X \subseteq S\) such that the sum of
integers in \(X\) equals \(k\).
Knapsack: Given a set of \(n\) items, each with a weight \(w_i\) and values \(v_i\), find a subset of items that fits in
a knapsack of capacity \(B\) and
maximizes the overall value of included items.
Weighted Interval Scheduling: Given a set of
intervals \((s_i,e_i, W_i)\) represent
as start and end times \(s_i\) and
\(e_i\), respectively, and weight \(W_i\), determine the maximum weight set of
non-overlapping intervals.
Minimum Edit Distance: Given two strings \(S\) and \(T\) over some alphabet of characters \(\Sigma\), determine the minimum number of
insertions or deletions needed to transform \(S\) to \(T\).
Matrix Chain Multiplication: Given a sequence of
matrices, determine the most efficient order in which to multiple
them
Can also look at some problems as having solution that can be built
by a sequence of choices of which elements to add to the solution. This
also allows for a more unified view in some cases between a greedy
approach and a DP approach. For example, in the Subset Sum
problem, we can imagine a strategy where we build a solution by picking
new elements from the original set to add to our output solution. We
might take some kind of greedy approach where we, for example, pick the
next smallest value and add it to our output. Clearly, the issue with
the greedy approach in this problem is that it can get “stuck”, with no
next choices that allow the solution to be rectified, even if a solution
does exist.
Stair Climbing
This is an example of a somewhat simpler DP problem but is good to
practice the basics. We are given a staircase, which can be represented
as simply a sequence of \(n\) steps,
each with an associated cost. You can start at either the 0th or 1st
step, and at each step you pay the cost of the current step and take
either 1 or 2 steps up. Given these rules, you want to find the path up
the stairs with minimal overall cost. This problem has a simple
recursive breakdown that is simpler in character to other path finding
problems, where the overall minimum cost solution can be represented in
terms minimum cost solution to smaller paths of the original problem.
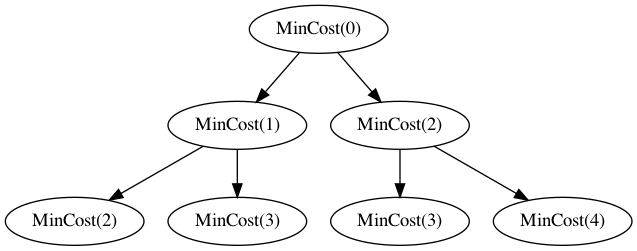
Basically, if we say \(\mathit{MinCost}(i)\) is the minimum cost
solution starting from step index \(i\), then we can represent this solution
recursively as \[\begin{aligned}
\mathit{MinCost}(i) = cost(i) + \mathit{Min}(\mathit{MinCost}(i+1),
\mathit{MinCost}(i+2))
\end{aligned}\] while also accounting for the base case where
\(i > n\), in which case this means
we’ve reached the top and can return cost 0.
If we expand the above recursion naively, though, it will contain an
exponential number of calls, though there are many shared subproblems,
similar to Fibonacci.
One simple approach here is to memoize solutions as we go, avoiding
the exponential work blowup.
Subset Sum
To understand the idea behind approach for Subset
Sum, can think about each element of the given list of \(n\) integers \(S=\{a_1,\dots,a_n\}\). If we wanted to come
up with a naive recursive solution, we could imagine the decision tree
for building all subsets of \(S\),
where each branch point represents whether we include that element or
not in the subset. This is one way to simply generate all possible
subsets of a given set. Within this tree, though, at each node, we can
imagine we are dealing with a subset of the original set, based on the
subset (e.g. suffix) of elements that we have not made a choice about
including or excluding. Along with this, we can imagine that each node
of the tree also has associated with it the “remaining target” amount,
which is the target minus the sum of elements included based on this
decision path in the tree. Now, even though this tree naively has size
(i.e, width) exponential in the number of elements, there are actually a
limited number of unique problems to solve in this tree, so there is
sufficient overlap between them to make this efficient.
The recursive formulation of subset sum can then be formulated as
follows, where \(SS(i,T)\) represents
the solution to subset sum for suffix \(S[i..]\) and target value \(T\): \[\begin{aligned}
SS(i, T) = SS(i+1, T-S[i]) \vee SS(i+1, T)
\end{aligned}\] representing the two possible decision branches
(i.e. include element \(i\) or don’t
include it). We can then compute this recursive formulation efficiently
by caching/memoizing results to \(SS(i,T)\) subproblems as we go.
Bottom Up Computation
Note that many problems of this character can be computed in either a
“top down” or “bottom up” fashion. In our recursive formulation, we are
formulating this top-down, since we are starting with larger problems
and breaking them down into smaller ones, and we can deal with
overlapping subproblems by caching/memoizing as we go. In a bottom up
approach, we can build a table of subproblems potentially starting with
smaller ones first. For example, in the subset sum problem, we can build
a \(n \times T\) table \(M\) where entry \(M[k][t]\) represents the solution to
problem with target sum \(t\) and
suffix \(S[k..]\) of elements starting
from index \(k\) from the original
array.
We know from our recursive formulation above that \[\begin{aligned}
M[k][t] = M[k+1][t-S[k]] \vee M[k+1][t]
\end{aligned}\] so we can use this to iteratively compute the
entries in the table until we arrive at the solution to the top level
problem.
Note, however, that in some cases computing such a table is actually
be slightly wasteful/unnecessary, even if it may still have good
asymptotic complexity. That is, when we go top down, we can typically
compute exactly the tree of subproblems that are actually needed for
solving the top level problem. When going bottom up in this tabular
fashion, though, we may actually end up computing solutions to some
additional, unused subproblems, that are technically never used to
compute the overall solution.
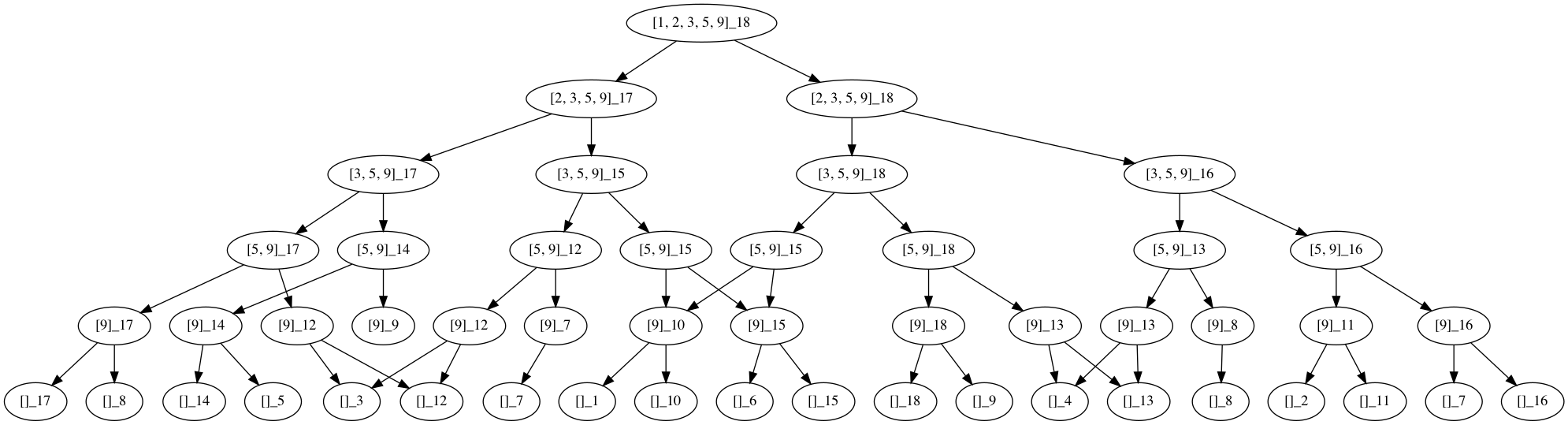
For example, here is a full recursion/decision tree for a subset sum
computed for \[S=\{1,2,3,5,9\},T=18\]
and then we can look at the same tree but with identical subproblem
nodes merged into one, illustrating the redundancy in subproblems:
In a bottom up approach, we would, instead of generating the
subproblems in this tree explicitly, just start at the “leaf" level of
this tree, compute the answers to those subproblems, and then work our
way up to the top, combining solutions to smaller subproblems as we go.
Note, though, that in the bottom row, for example, we never encounter a
\((\{9\},6)\) subproblem, even though
it may be computed in the bottom up approach.
Knapsack
0-1 Knapsack is very similar to Subset Sum i.e., we have to determine
if there exists a subset of \(n\) given
items with corresponding weights and values \((w_i,v_i)\), that remains under our given
capacity and maximizes the sum of the chosen item values. Indeed, we can
think of Subset Sum as a special case of the knapsack
problem, where the values and weights of each element are the same. As
in Subset Sum case, we can imagine a solution search
tree where we either include or exclude the first element, and the
subproblems we recurse on are basically the rest of the elements with a
capacity reduced by that of our first element, or the rest of the
elements with the original capacity. Again, this tree might grow
exponentially, but, if our capacity is \(C\), we actually only have at most \(C\) unique possible capacities, and at most
\(n\) suffixes of elements. Note also
that the minor difference from Subset Sum is that, when we combine
solutions to recursive subproblems, we want to take the maximum solution
(since this is an optimization problem variant), rather than just taking
the disjunction. So, the recursive formulation is as follows \[\begin{aligned}
&\textsc{Knapsack}(S,C,i) =
\begin{cases}
\textsc{Knapsack}(S,C, i-1) \text{ if } (C-w_i) \leq 0 \\
Max
\begin{cases}
v_1 + \textsc{Knapsack}(S,C-w_i,i-1) \text{ if } (C-w_i)
> 0 \\
\textsc{Knapsack}(S,C,i-1) \\
\end{cases}
\end{cases}\\
\end{aligned}\]
Longest Increasing Subsequence
Problem: Given an array of size \(n\), find the length of the longest
increasing subsequence i.e., the longest possible subsequence in which
the elements of the subsequence are sorted in increasing order.
Solution Idea: If we consider any increasing
subsequence, we can always naturally extend it with an earlier, smaller
element in the array. So, if we have a longest possible subsequence for
a suffix of our original array, we should be able to potentially extend
it with with an earlier element that is smaller than the minimum element
of this subsequence. (TODO: Think more about the above
reasoning?)
General Technique
Overall, one high-level, general approach to solving problems
amenable to a dynamic programming can be viewed as follows:
Is it a decision or optimization problem?
Define the recursive formulation of the problem i.e., how you
would define the solution to a larger problem in terms of smaller
subproblems. (i.e. optimal substructure)
Identify any sharing between subproblems. (i.e. overlapping
subproblems)
Decide on an implementation strategy: top-down or bottom
up.
N.B. It is important to remember to first formulate the problem
abstractly in terms of the inductive/recursive structure, then think
about it in terms of how substructure is shared in a DAG, and only then
worry about coding strategies.