Towards Autonomous Protocol Proofs
Writing formal proofs for distributed protocols is tedious and usually not worth the effort for real-world systems. In general, you have to come up with an inductive invariant which is already a very difficult task. At least a few separate PhD theses were entirely devoted to automating this task in the past few years, and they still usually don’t scale beyond protocols of a moderate size. After coming up with an inductive invariant, you then also need to prove that invariant is actually inductive, which on its own can be another difficult task. In most cases, even automating this checking step is undecidable.
If you can’t give the inductive invariant to an SMT solver and have it automatically solved, you need to put in some manual effort to essentially write a detailed proof yourself, with the help of a proof assistant. In TLA+, doing this kind of proof via the TLA+ proof system (TLAPS) is feasible, but a major challenge for any nontrival protocols.
In some prior research, we worked on better ways to come up with inductive invariants, and one product of this work was an inductive invariant for an abstract specification of the Raft protocol in TLA+.
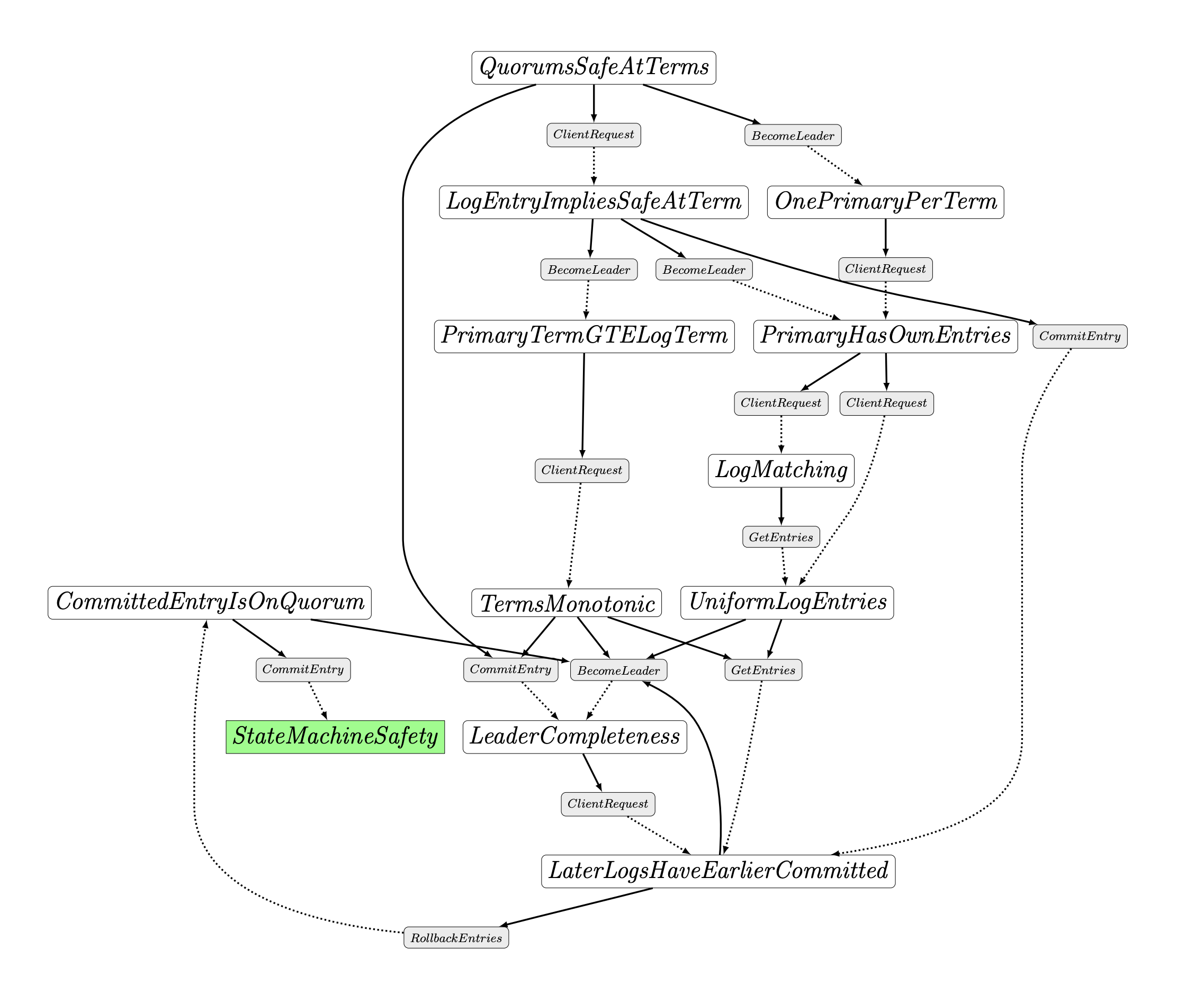
The invariant consists of 12 smaller lemma invariants (definitions found here), and cannot be automatically verified by the TLA+ proof system (TLAPS). You can try to use TLC (for tiny protocols) or Apalache for verifying the correctness for finite versions of the protocol (e.g. finite number of nodes), but none of these give you a full, general machine-checked proof of correctness.
In recent experiments when re-checking these proofs, the latest Claude models (Opus 4.6) appear to do an excellent job of automatically writing TLAPS proofs for this. In the past, and from direct experience working on this during older research projects, this was typically at least weeks or months of effort for a highly capable master’s or PhD student. It is meticulous and mentally taxing work for humans to carry out, and can be a huge time sink.
We can give our candidate inductive invariant and a skeleton TLAPS proof to Claude, along with a few basic agent instructions about how to run TLAPS to check proof obligations. The ultimate goal is to check the induction proof step for each separate lemma and each action of the protocol. We can let Claude Code go with this, asking it to prove each of the 12 top-level theorems, one by one, and to give us a nicely formatted report of its results upon completion.
After around 4 hours of total runtime, with almost no human interaction, Claude was able to complete successful proofs for all of the 12 top-level theorems. The complete file with finished proofs is around 1720 lines, up from a baseline of 296 lines in the starting unproven skeleton file.
Proof Progress
Overall, each theorem required roughly no more than 30-40 minutes of thinking time, with basically zero human intervention. Initially it skipped over an obligation for one of the theorems, but with simple prodding was able to go back and try again and easily resolve it in a minute or so. The final version of the generated proof is on this branch, along with associated commits made as it proved each theorem. Details on individual theorem proof stats are shown in the table below.
Theorem Summary
| Theorem | Invariant | Obligations | SMT | Zenon | TLAPM | Prover Time | Claude Time | Attempts |
|---|---|---|---|---|---|---|---|---|
| L_1 | H_OnePrimaryPerTerm | 139/139 | 47 | 2 | 90 | 11.9s | ~8 min | 8 |
| L_2 | H_PrimaryHasOwnEntries | 182/182 | 63 | 0 | 119 | 2.4s | ~10 min | 4 |
| L_3 | H_LogMatching | 21/21 | 7 | 0 | 14 | 1.3s | ~4 min | 2 |
| L_4 | H_PrimaryTermGTELogTerm | 95/95 | 37 | 0 | 58 | 1.7s | ~15 min | 9 |
| L_5 | H_QuorumsSafeAtTerms | 132/132 | 132 | 0 | 0 | cached | ~12 min | 6 |
| L_6 | H_UniformLogEntries | 640/640 | 640 | 0 | 0 | cached | ~58 min | — |
| L_7 | H_TermsMonotonic | 227/227 | 227 | 0 | 0 | cached | ~8 min | 6 |
| L_8 | H_LogEntryImpliesSafeAtTerm | 20/20 | 20 | 0 | 0 | cached | ~2 min | — |
| L_9 | H_LeaderCompleteness | 418/418 | 159 | 0 | 257 | 4.1s | ~36 min | — |
| L_10 | H_LaterLogsHaveEarlierCommitted | 422/422 | 131 | 0 | 291 | cached | ~45 min | 8 |
| L_11 | H_CommittedEntryIsOnQuorum | 125/125 | 125 | 0 | 0 | cached | ~15 min | — |
| L_12 | H_StateMachineSafety | 138/138 | 54 | 0 | 84 | cached | ~12 min | 3 |
It is also interesting to observe some of the generated proofs in detail, which are quite nontrivial. For example, the longest individual theorem proof for THEOREM L_6 (took Claude ~58 minutes) contains over 390 lines of TLAPS proof code, with a variety of fine-grained proof arguments and decomposition steps. It is difficult to imagine a human expert developing the same proof in a comparable amount of time.
There are definitely a few caveats here, but the results are impressive, and something outside the realm of possibility a few years ago. First, there is a lot of information about the Raft protocol on the web, and it is probably one of the most well-studied and widely implemented consensus protocols to date. Similarly, there has been some amount of work done on formally verified Raft proofs. This work is not done specifically in TLA+, but there is prior work in the area. Having said that, I still think this is still super impressive. Even for an experienced engineer/researcher, going off and reading documentation on existing Raft proofs and synthesizing that into a correct TLAPS proof would be an extremely nontrivial task.
From a practical systems engineering and building standpoint, I’m also not too interested in fully automated proofs. That is, I often still find that finite-state model checking over adequately large state spaces is still a better cost-benefit tradeoff, and makes things much easier to automate and re-verify upon modification. Also, I am still quite unconvinced that we will ever be able to (or care about) proving properties of runnable system implementation code. Regardless, this task is a great benchmark for understanding the frontier capabilities of these models.
Another issue that increasingly comes to mind is the speed bottlenecks on these models. Right now, the execution loops feel roughly in line with the speed of a human, or at least comprehensible to a human. But, for tasks that are largely inference bottlenecked, it is interesting to think about what is possible if these kind of tasks are massively parallelizable and/or can run at 100x or 1000x their current speed. This calculus also leads to other interesting questions about the role of specialized algorithms i.e. we have done deep research and development on intricate and efficient algorithms for automatically model checking these types of protocols. But, if we can run a general (super) intelligence at 1000x human speed, do these kind of specialized algorithms become increasingly less necessary? Special purpose algorithms might always be more efficient for specific tasks, but in a world where the cost of compute continues to fall we might not care that much, especially if the AI-driven methods are more flexible and general.